-
公众号

大家好,Mysql 是大家最常用的数据库,下面为大家带来 mysql 主从同步知识点的分享,以便巩固 mysql 基础知识,如有错误,还请各位大佬们指正。
MySQL 主从同步,即 MySQL Replication,可以实现将数据从一台数据库服务器同步到多台数据库服务器。MySQL 数据库自带主从同步功能,经过配置,可以实现基于库、表结构的多种方案的主从同步。
Redis 是一种高性能的内存数据库,但不是今天的主角;MySQL 是基于磁盘文件的关系型数据库,相比于 Redis 来说,读取速度会慢一些,但是功能强大,可以用于存储持久化的数据。在实际工作中,我们常将 Redis 作为缓存与 MySQL 配合来使用,当有数据访问请求的时候,首先会从缓存中进行查找,如果存在就直接取出,如果不存在再访问数据库,这样就提升了读取的效率,也减少了后端数据库的访问压力。使用 Redis 这种缓存架构是高并发架构中非常重要的一环。
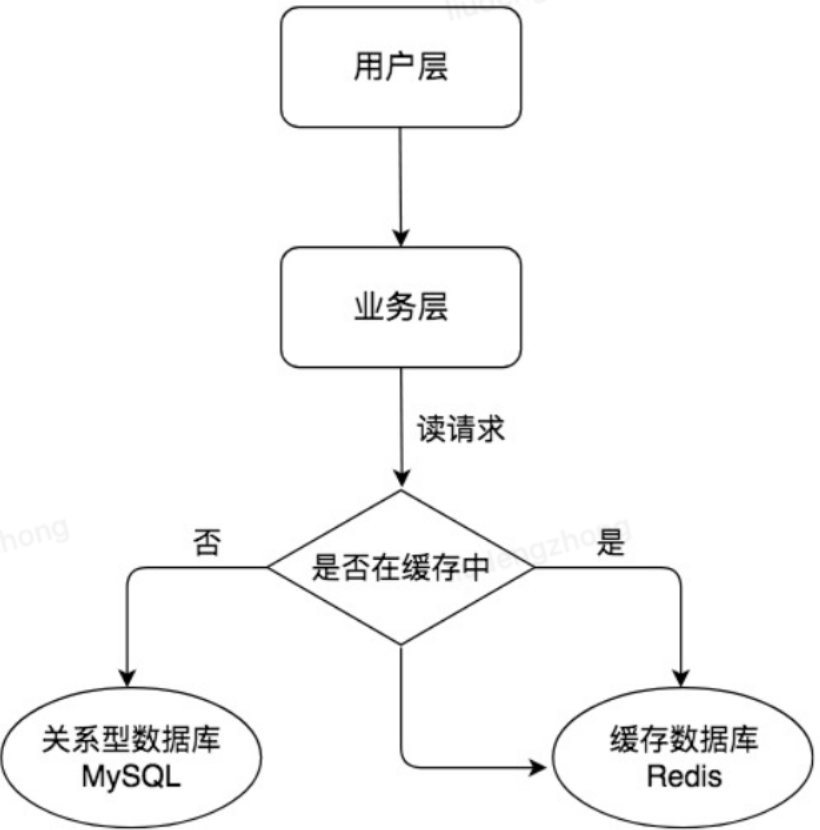
随着业务量的不断增长,数据库的压力会不断变大,缓存的频繁变更也强依赖于数据的查询结果,导致数据查询效率低,负载很高,连接过多等问题。对于电商场景来说,往往存在很多典型的读多写少场景,我们可以对 MySQL 做主从架构并且进行读写分离,让主服务器(Master)处理写请求,从服务器(Slave)处理读请求,这样可以进一步提升数据库的并发处理能力。如下图:
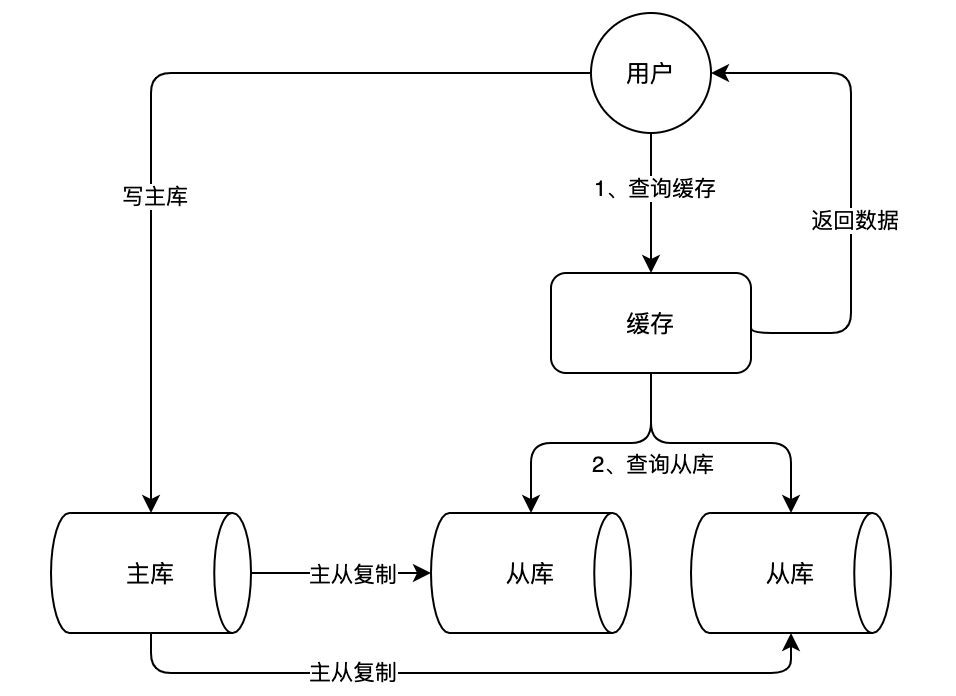
上图中,可以看到,我们增加了 2 个从库,这 2 个从库可以一起抗下大量的读请求,分担主库压力。从库会通过主从复制,从主库中不断的同步数据,以此来保证从库的数据和主库数据的一致。
接下来,我们看看主从同步有哪些作用,以及主从同步具体是怎么实现的。
一般来说,不是所有的系统都需要对数据库进行主从架构的设计,因为架构本身是有一定成本的,如果我们的目的在于提升数据库高并发访问的效率,那么我们首先应该优化 SQL 语句及索引,充分发挥数据库的最大性能;其次是采用缓存的策略,如使用 Redis、MongoDB 等缓存工具,通过其高性能的优势把数据保存在内存数据库中,提升读取的效率,最后才是对数据库采用主从架构,进行读写分离。系统的使用和维护成本是根据架构的升级逐渐升高的。
言归正传,主从同步不仅可以提升数据库的吞吐量,还有以下三个方面的作用:
我们可以通过主从复制的方式来同步数据,然后通过读写分离提升数据库的并发处理能力。简单来说就是我们的数据被放在了多个数据库中,其中一个是 Master 主库,其余的是 Slave 从库。当主库数据变化时,会自动将数据同步到从库中,而我们程序可以从从库读取数据,也就是采用读写分离的方式。电商的应用往往是 “读多写少”,采用读写分离就实现了更高的并发访问。原本所有的读写压力都由一台服务器承担,现在有多个服务器共同处理读请求,减少了对主库的压力。另外还可以对从服务器进行负载均衡,让不同的读请求按照策略均匀的分配到不同的从服务器中,让读取更加顺畅。读取顺畅的另一个原因,就是减少了锁表的影响,比如我们让主库负责写,当主库出现写锁的时候,不会影响到从库的查询操作。
主从同步也相当于是一种数据热备份机制,在主库正常运行下进行备份,不影响提供数据服务。
数据备份实际就是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,当服务器出现故障、宕机等无可用的情况下,可以迅速进行故障切换,让从库充当主库,保障服务正常运行。大家可以了解下电商系统数据库高可用 SLA 指标。
说到主从同步的原理,我们就需要了解在数据库中的一个重要日志文件,就是 Binlog 二进制文件,它记录了对数据库进行更新的事件,事实上主从同步的原理就是基于 Binlog 进行数据同步的。
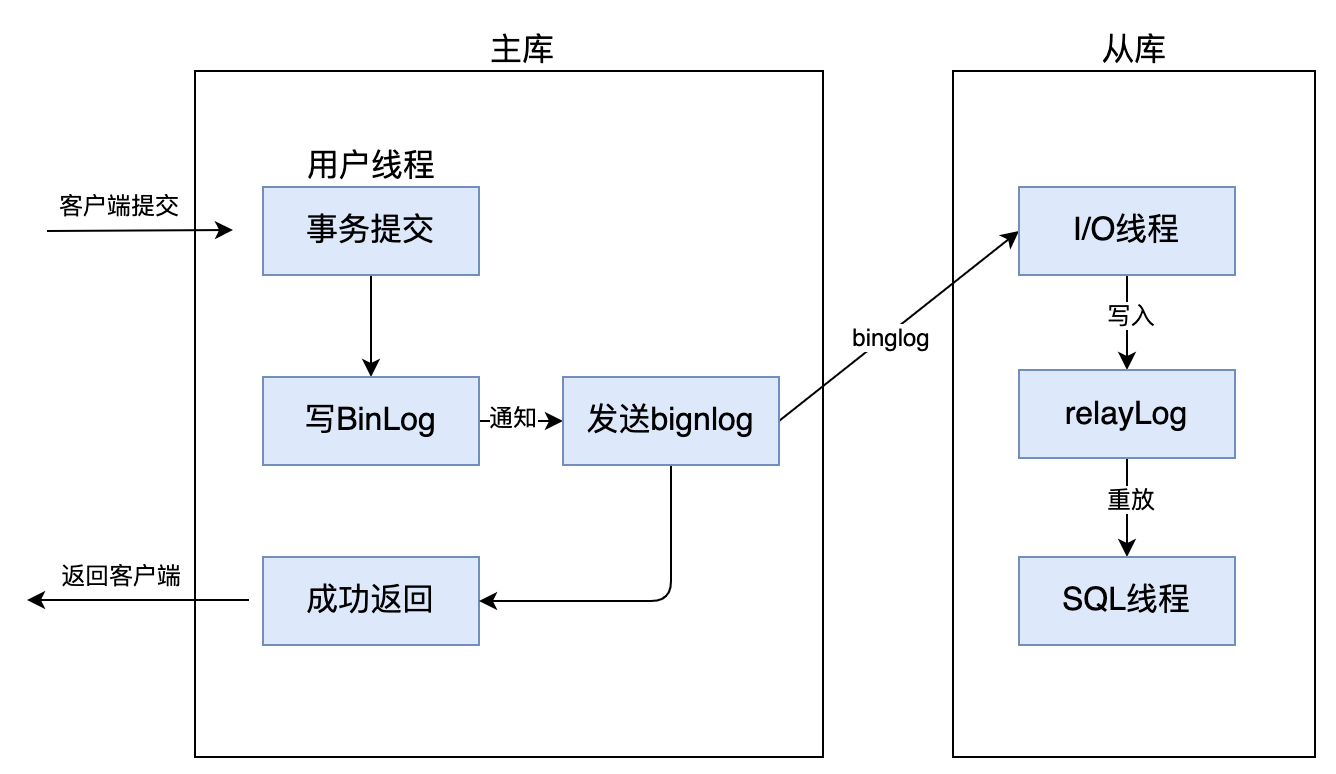
在主从复制的过程中,会基于三个线程来操作,一个是 binlog dump 线程,位于 master 节点上,另外两个线程分别是 I/O 线程和 SQL 线程,它们都分别位于 slave 节点上,如下图:
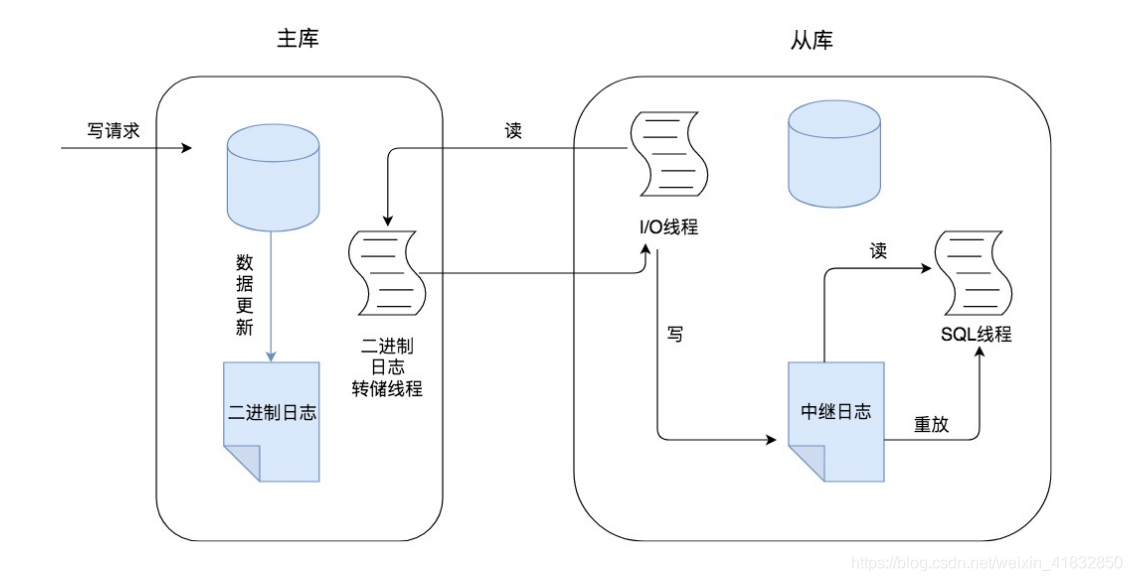
结合以上图片,我们一起来了解主从复制的核心流程:
当 master 节点接收到一个写请求时,这个写请求可能是增删改操作,此时会把写请求的更新操作都记录到 binlog 日志中。
master 节点会把数据复制给 slave 节点,如图中的 slave01 节点和 slave02 节点,这个过程,首先得要每个 slave 节点连接到 master 节点上,当 slave 节点连接到 master 节点上时,master 节点会为每一个 slave 节点分别创建一个 binlog dump 线程,用于向各个 slave 节点发送 binlog 日志。
binlog dump 线程会读取 master 节点上的 binlog 日志,然后将 binlog 日志发送给 slave 节点上的 I/O 线程。当主库读取事件的时候,会在 Binglog 上加锁,读取完成之后,再将锁释放掉。
slave 节点上的 I/O 线程接收到 binlog 日志后,会将 binlog 日志先写入到本地的 relaylog 中,relaylog 中就保存了 binlog 日志。
slave 节点上的 SQL 线程,会来读取 relaylog 中的 binlog 日志,将其解析成具体的增删改操作,把这些在 master 节点上进行过的操作,重新在 slave 节点上也重做一遍,达到数据还原的效果,这样就可以保证 master 节点和 slave 节点的数据一致性了。
主从同步的数据内容其实是二进制日志(Binlog),它虽然叫二进制日志,实际上存储的是一个又一个的事件(Event),这些事件分别对应着数据库的更新操作,比如 INSERT、UPDATE、DELETE 等。
另外我们还需要注意的是,不是所有版本的 MySQL 都默认开启了服务器的二进制日志,在进行主从同步的时候,我们需要先检查服务器是否已经开启了二进制日志。
二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在一些延迟,比如 200ms,这样就可能造成用户在从库上读取的数据不是最新的数据,也就会造成主从同步中的数据不一致的情况发生。比如我们对一条记录进行更新,这个操作是在主库上完成的,而在很短的时间内,比如 100ms,又对同一个记录进行读取,这时候从库还没有完成数据的同步,那么,我们通过从库读取到的数据就是一条旧的数据。这种情况下该怎么办呢?
可以想象下,如果我们想要操作的数据都存储在同一个数据库中,那么对数据进行更新的时候,可以对记录进行加写锁,这样在读取的时候就不会发生数据不一致的情况了。但这时从库的作用就是备份数据,没有做到读写分离,分担主库的压力。
因此我们还需要想办法,在进行读写分离的时候,解决主从同步中数据不一致的问题,也就是解决主从之间数据复制方式的问题,如果按照数据一致性从弱到强来进行划分,有以下三种复制方式。
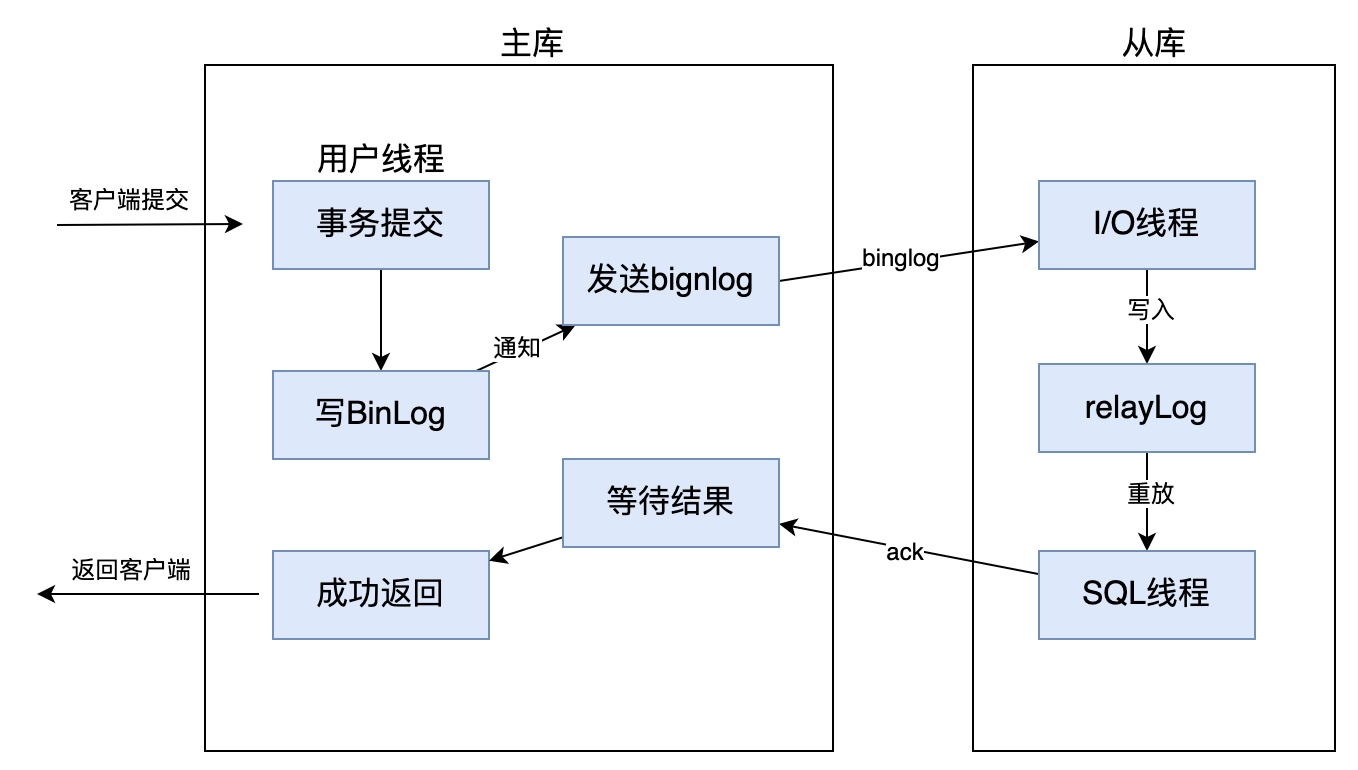
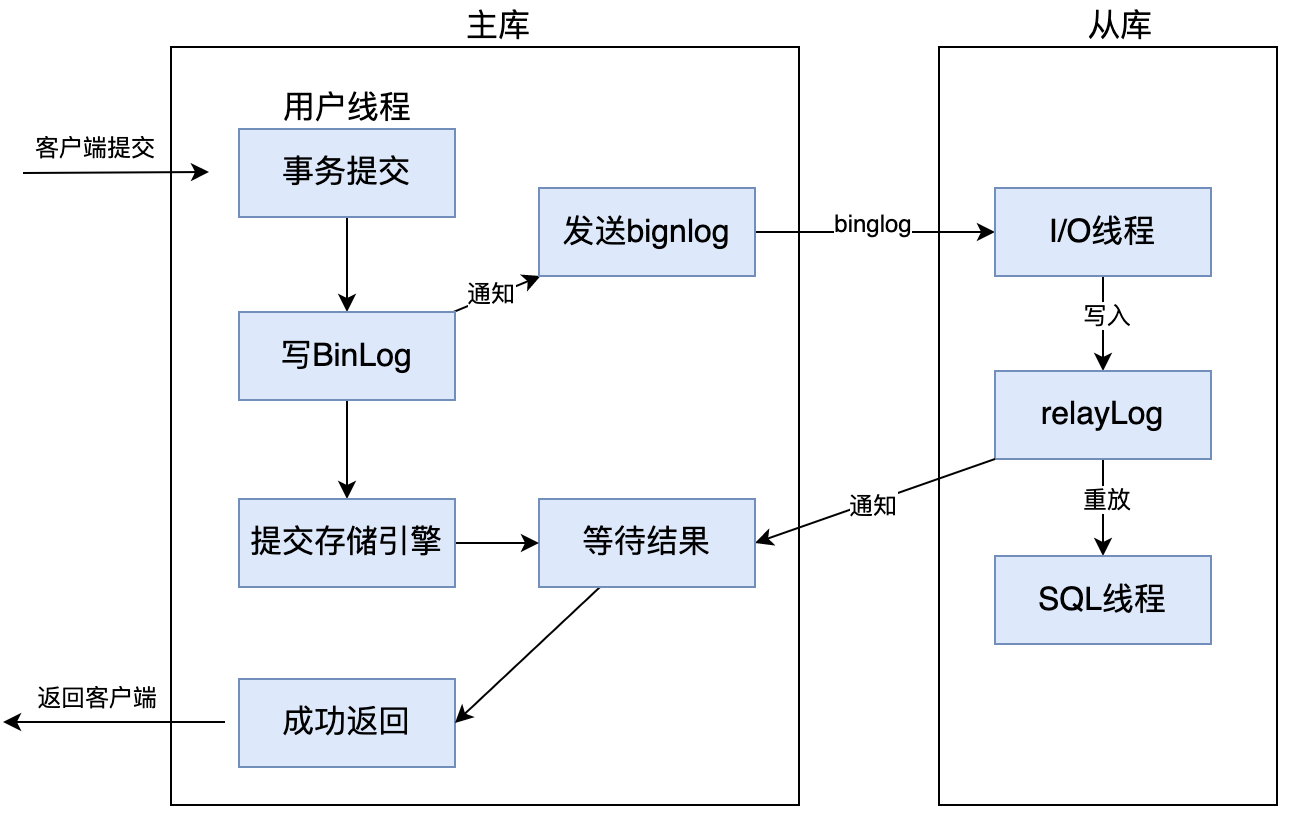
首先,全同步复制,就是当主库执行完一个事务之后,要求所有的从库也都必须执行完该事务,才可以返回处理结果给客户端;因此,虽然全同步复制数据一致性得到保证了,但是主库完成一个事物需要等待所有从库也完成,性能就比较低了。如下图:
5.2 异步复制
而异步复制,就是当主库提交事物后,会通知 binlog dump 线程发送 binlog 日志给从库,一旦 binlog dump 线程将 binlog 日志发送给从库之后,不需要等到从库也同步完成事务,主库就会将处理结果返回给客户端。
因为主库只管自己执行完事务,就可以将处理结果返回给客户端,而不用关心从库是否执行完事务,这就可能导致短暂的主从数据不一致的问题了,比如刚在主库插入的新数据,如果马上在从库查询,就可能查询不到。
而且,当主库提交事物后,如果宕机挂掉了,此时可能 binlog 还没来得及同步给从库,这时候如果为了恢复故障切换主从节点的话,就会出现数据丢失的问题,所以异步复制虽然性能高,但数据一致性上是最弱的。
mysql 主从复制,默认采用的就是异步复制这种复制策略。
MySQL5.5 版本之后开始支持半同步复制的方式。原理是在客户端提交 COMMIT 之后不直接将结果返回给客户端,而是等待至少有一个从库收到了 Binlog,并且写入到中继日志中,再返回给客户端。这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
在 MySQL5.7 版本中还增加了一个 rpl_semi_sync_master_wait_for_slave_count 参数,我们可以对需要响应的从库数量进行设置,默认为 1,也就是说只要有一个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。
但是,半同步复制也存在以下几个问题:
半同步复制的性能,相比异步复制而言有所下降,相比于异步复制是不需要等待任何从库是否接收到数据的响应,而半同步复制则需要等待至少一个从库确认接收到 binlog 日志的响应,性能上是损耗更大的。
主库等待从库响应的最大时长是可以配置的,如果超过了配置的时间,半同步复制就会变成异步复制,那么,异步复制的问题同样也就会出现了。
在 MySQL 5.7.2 之前的版本中,半同步复制存在着幻读问题的。
当主库成功提交事物并处于等待从库确认的过程中,这个时候,从库都还没来得及返回处理结果给客户端,但因为主库存储引擎内部已经提交事务了,所以,其他客户端是可以到从主库中读到数据的。
但是,如果下一秒主库突然挂了,此时正好下一次请求过来,因为主库挂了,就只能把请求切换到从库中,因为从库还没从主库同步完数据,所以,从库中当然就读不到这条数据了,和上一秒读取数据的结果对比,就造成了幻读的现象了。
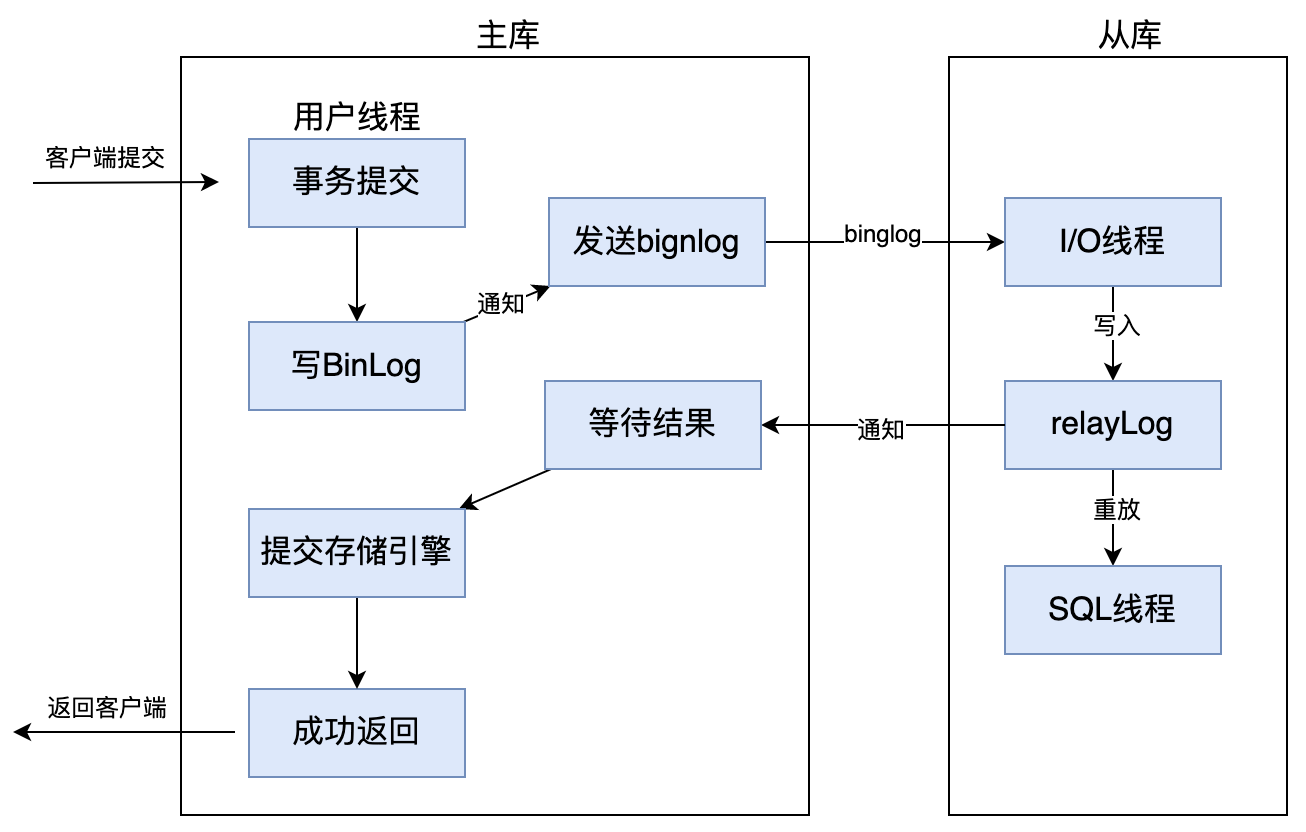
增强半同步复制,是 mysql 5.7.2 后的版本对半同步复制做的一个改进,原理上几乎是一样的,主要是解决幻读的问题。
主库配置了参数 rpl_semi_sync_master_wait_point = AFTER_SYNC 后,主库在存储引擎提交事务前,必须先收到从库数据同步完成的确认信息后,才能提交事务,以此来解决幻读问题。参考下图:
通过上述内容,我们了解了 Mysql 数据库的主从同步,如果你的目标仅是数据库的高并发,那么可以先从 SQL 优化,索引以及 Redis 缓存数据等这些方面来考虑优化,然后再考虑是否采用主从架构的方式。
在主从架构的配置中,如果想要采取读写分离的策略,我们可以自己编写程序,也可以通过第三方的中间件来实现。
自己编写程序的好处就在于比较自主,我们可以自己判断哪些查询在从库上来执行,针对实时性要求高的需求,我们还可以考虑哪些查询可以在主库上执行。同时程序直接连接数据库,减少了中间件层,可以减少一些性能损耗。
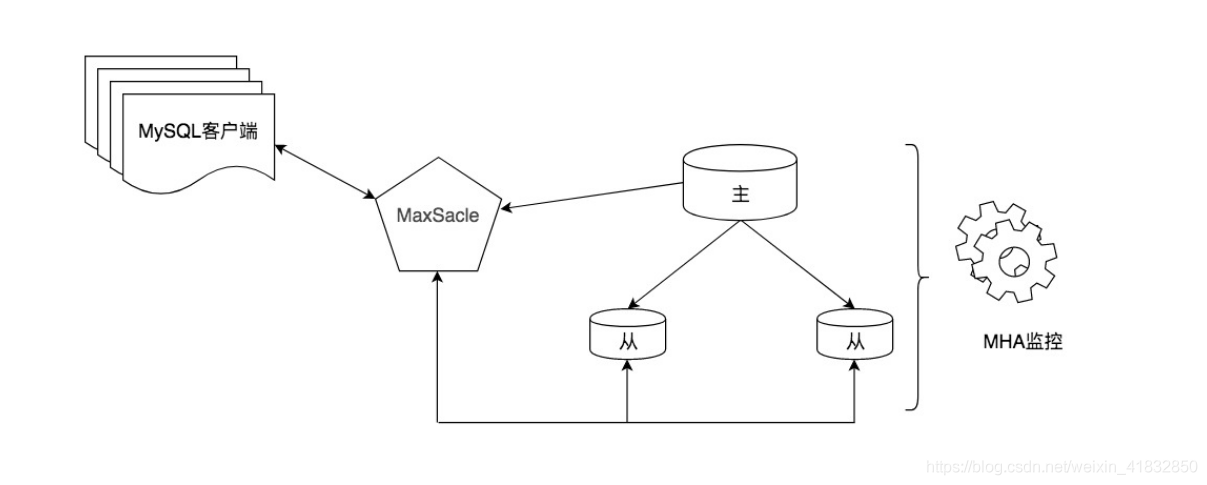
而采用中间件的方法有很明显的优势,功能强大,使用简单。但因为在客户端和数据库之间增加了中间件层会有一些性能损耗,同时商业中间件价格较高,有一定学习成本。另外,我们也可以考虑采用一些优秀的开源工具,比如 MaxScale。它是 MariaDB 开发的 MySQL 数据中间件。比如在下图中,使用 MaxScale 作为数据库的代理,通过路由转发完成了读写分离。同时我们也可以使用 MHA 工具作为强一致的主从切换工具,从而完成 MySQL 的高可用架构。